








Um engenheiro de software explica a ciência por trás de recomendações personalizadas de música.
Veja mais sobre
- Facebook comanda quantos app
- Clonagem de Whatsapp
- O que o Google sabe sobre você?
- Roubo de dados em aplicativos

Sou um grande fã do Spotify e particularmente do Discover Weekly. Por quê? Isso me faz sentir visto. Ele conhece o meu musical tem um gosto melhor do que qualquer pessoa em toda a minha vida sempre tem, e eu estou sempre encantado pela forma como satisfatoriamente apenas para a direita é a cada semana, com faixas eu provavelmente nunca teria me encontrado ou conhecido que eu gostaria.
Para aqueles de vocês que vivem sob uma rocha insonorizada, deixe-me apresentá-lo ao meu melhor amigo virtual:
 |
| Uma lista de reprodução Spotify Discover Weekly - especificamente, a minha. |
Como se constata, não estou sozinho em minha obsessão com a Discover Weekly . A base de usuários fica louca por isso, o que levou a Spotify a repensar seu foco e a investir mais recursos em playlists baseadas em algoritmos.
Então, como o Spotify faz um trabalho incrível ao escolher essas 30 músicas para cada pessoa a cada semana? Vamos diminuir o zoom por um segundo para ver como outros serviços de música abordaram as recomendações musicais e como o Spotify está melhorando.
Uma Breve História da Curadoria Musical Online

Nos anos 2000, Songza iniciou a cena de curadoria de música on-line usando curadoria manual para criar listas de reprodução para os usuários. Isso significava que uma equipe de "especialistas em música" ou outros curadores humanos reuniam listas de reprodução que eles achavam que soavam bem e que os usuários ouviam essas listas de reprodução. (Posteriormente, a Beats Music empregaria essa mesma estratégia.) A curadoria manual funcionou bem, mas foi baseada nas escolhas específicas do curador e, portanto, não pôde levar em conta o gosto musical individual de cada ouvinte.
Como Songza, Pandora também foi um dos atores originais da curadoria de música digital. Empregou uma abordagem um pouco mais avançada, em vez de marcar manualmente os atributos das músicas. Isso significava que um grupo de pessoas ouvia música, escolheu um monte de palavras descritivas para cada faixa e marcou as faixas de acordo. Então, o código do Pandora poderia simplesmente filtrar por certas tags para criar listas de músicas de sons semelhantes.
Na mesma época, nasceu uma agência de inteligência musical do MIT Media Lab, chamada The Echo Nest , que adotou uma abordagem radical e de ponta à música personalizada. O Echo Nest usou algoritmos para analisar o conteúdo de áudio e texto da música, permitindo a identificação de músicas, recomendações personalizadas, criação de listas de reprodução e análise.
Finalmente, outra abordagem é o Last.fm, que ainda existe hoje e usa um processo chamado filtragem colaborativa para identificar a música que seus usuários podem gostar, mas mais sobre isso em um momento.
Então, se é assim que outros serviços de curadoria de música lidam com recomendações, como funciona o mecanismo de mágica do Spotify ? Como é que parece que os gostos dos utilizadores individuais são mais precisos do que os outros serviços?
Três tipos de modelos de recomendação do Spotify
O Spotify não usa realmente um único modelo de recomendação revolucionário. Em vez disso, eles combinam algumas das melhores estratégias usadas por outros serviços para criar seu próprio mecanismo de descoberta excepcionalmente poderoso.
Para criar o Discover Weekly, existem três tipos principais de modelos de recomendação que o Spotify emprega:
- Modelos de Filtragem Colaborativa (ou seja, aqueles que o Last.fm usou originalmente), que analisam tanto o seu comportamento quanto os comportamentos dos outros .
- Modelos de Processamento de Linguagem Natural (PNL) , que analisam o texto.
- Modelos de áudio , que analisam as próprias faixas de áudio brutos .

Fonte da imagem: Já se perguntou como o Spotify descobre trabalhos semanais? Data Science , via Galvanize.
Vamos mergulhar em como cada um desses modelos de recomendação funciona!

Primeiro, alguns antecedentes: quando as pessoas ouvem as palavras “filtragem colaborativa”, geralmente pensam no Netflix, já que foi uma das primeiras empresas a usar esse método para alimentar um modelo de recomendação, levando as classificações de filmes dos usuários para informar seus compreensão de quais filmes recomendar a outros usuários semelhantes.
Depois que o Netflix foi bem-sucedido, o uso de filtragem colaborativa se espalhou rapidamente e agora é frequentemente o ponto de partida para qualquer pessoa que esteja tentando criar um modelo de recomendação.
Ao contrário do Netflix, o Spotify não tem um sistema baseado em estrelas com o qual os usuários classificam suas músicas. Em vez disso, os dados do Spotify são feedback implícito - especificamente, as contagens de fluxodas faixas e dados adicionais de streaming, como se um usuário salvou a faixa em sua própria lista de reprodução ou visitou a página do artista depois de ouvir uma música.
Mas o que é a filtragem colaborativa, verdadeiramente, e como funciona? Aqui está um resumo de alto nível, explicado em uma conversa rápida:

Alguma matemática complicada ...
Quando termina, acabamos com dois tipos de vetores, representados aqui por X e Y. X é um vetor de usuário , representando o gosto de um único usuário, e Y é um vetor de música , representando o perfil de uma única música.
Fonte da imagem: Tristan Jehan e David DesRoches, via The Echo Nest .
Em última análise, esta leitura das principais características da música permite ao Spotify entender semelhanças fundamentais entre as músicas e, portanto, quais usuários podem aproveitá-las, com base em seu próprio histórico de audição.
Isso abrange as noções básicas dos três principais tipos de modelos de recomendação que alimentam o Pipeline de Recomendações do Spotify e, em última análise, aciona a lista de reprodução do Discover Weekly!

É claro, esses modelos de recomendação estão todos conectados ao ecossistema maior do Spotify, que inclui grandes quantidades de armazenamento de dados e usa muitos clusters do Hadoop para escalar recomendações e fazer com que esses mecanismos trabalhem em matrizes enormes, infinitos artigos de música on-line e grande número de arquivos de áudio .
Espero que isso tenha sido informativo e tenha despertado sua curiosidade como se fosse minha. Por enquanto, estarei trabalhando em meu próprio Discover Weekly, encontrando minha nova música favorita enquanto aprecio todo o aprendizado de máquina que está ocorrendo nos bastidores. 🎶
Vamos mergulhar em como cada um desses modelos de recomendação funciona!
Modelo de recomendação nº 1: filtragem colaborativa
Primeiro, alguns antecedentes: quando as pessoas ouvem as palavras “filtragem colaborativa”, geralmente pensam no Netflix, já que foi uma das primeiras empresas a usar esse método para alimentar um modelo de recomendação, levando as classificações de filmes dos usuários para informar seus compreensão de quais filmes recomendar a outros usuários semelhantes.
Depois que o Netflix foi bem-sucedido, o uso de filtragem colaborativa se espalhou rapidamente e agora é frequentemente o ponto de partida para qualquer pessoa que esteja tentando criar um modelo de recomendação.
Ao contrário do Netflix, o Spotify não tem um sistema baseado em estrelas com o qual os usuários classificam suas músicas. Em vez disso, os dados do Spotify são feedback implícito - especificamente, as contagens de fluxodas faixas e dados adicionais de streaming, como se um usuário salvou a faixa em sua própria lista de reprodução ou visitou a página do artista depois de ouvir uma música.
Mas o que é a filtragem colaborativa, verdadeiramente, e como funciona? Aqui está um resumo de alto nível, explicado em uma conversa rápida:
Fonte da imagem: Filtragem Colaborativa no Spotify , por Erik Bernhardsson, ex-Spotify.
Oque esta acontecendo aqui? Cada um desses indivíduos tem preferências de faixa: o da esquerda gosta das faixas P, Q, R e S, enquanto o da direita gosta das faixas Q, R, S e T.
A filtragem colaborativa usa esses dados para dizer:
“Hmmm… Vocês dois gostam de três das mesmas faixas - Q, R e S - então vocês provavelmente são usuários similares. Portanto, é provável que você goste de outras faixas que a outra pessoa ouviu, que você ainda não ouviu. ”
Portanto, sugere-se que o da direita verifique a faixa P - a única faixa não mencionada, mas que a sua contraparte “similar” gostava - e a da esquerda verifique a faixa T, pelo mesmo raciocínio. Simples, certo?
Mas como o Spotify realmente usa esse conceito na prática para calcular as trilhas sugeridas de milhões de usuários com base nas milhões de preferências de outros usuários?
Com matemática matricial, feito com bibliotecas Python!

Na verdade, essa matriz que você vê aqui é gigantesca . Cada linha representa um dos 140 milhões de usuários do Spotify - se você usa o Spotify, você mesmo é uma linha nessa matriz - e cada coluna representa uma das 30 milhões de músicas no banco de dados do Spotify.
Em seguida, a biblioteca Python executa essa fórmula de fatoração de matriz longa e complicada:


Oque esta acontecendo aqui? Cada um desses indivíduos tem preferências de faixa: o da esquerda gosta das faixas P, Q, R e S, enquanto o da direita gosta das faixas Q, R, S e T.
A filtragem colaborativa usa esses dados para dizer:
“Hmmm… Vocês dois gostam de três das mesmas faixas - Q, R e S - então vocês provavelmente são usuários similares. Portanto, é provável que você goste de outras faixas que a outra pessoa ouviu, que você ainda não ouviu. ”
Portanto, sugere-se que o da direita verifique a faixa P - a única faixa não mencionada, mas que a sua contraparte “similar” gostava - e a da esquerda verifique a faixa T, pelo mesmo raciocínio. Simples, certo?
Mas como o Spotify realmente usa esse conceito na prática para calcular as trilhas sugeridas de milhões de usuários com base nas milhões de preferências de outros usuários?
Com matemática matricial, feito com bibliotecas Python!
Na verdade, essa matriz que você vê aqui é gigantesca . Cada linha representa um dos 140 milhões de usuários do Spotify - se você usa o Spotify, você mesmo é uma linha nessa matriz - e cada coluna representa uma das 30 milhões de músicas no banco de dados do Spotify.
Em seguida, a biblioteca Python executa essa fórmula de fatoração de matriz longa e complicada:
Alguma matemática complicada ...
Quando termina, acabamos com dois tipos de vetores, representados aqui por X e Y. X é um vetor de usuário , representando o gosto de um único usuário, e Y é um vetor de música , representando o perfil de uma única música.
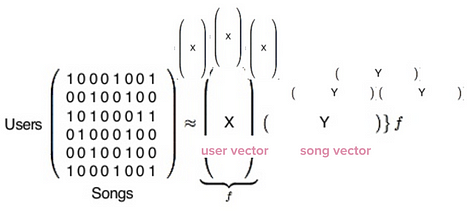 |
| A matriz User / Song produz dois tipos de vetores: vetores de usuário e vetores de música. Fonte da imagem: Da ideia à execução: Spotify's Discover Weekly , de Chris Johnson, ex-Spotify. |
Agora temos 140 milhões de vetores de usuários e 30 milhões de vetores de músicas. O conteúdo real desses vetores é apenas um monte de números que são essencialmente sem sentido por conta própria, mas são extremamente úteis quando comparados.
Para descobrir quais gostos musicais dos usuários são mais parecidos com os meus, a filtragem colaborativa compara meu vetor com todos os vetores dos outros usuários, definindo quais usuários são as correspondências mais próximas. O mesmo vale para o vetor Y, músicas : você pode comparar o vetor de uma única música com todas as outras e descobrir quais músicas são mais parecidas com a que está em questão.
A filtragem colaborativa faz um bom trabalho, mas o Spotify sabia que eles poderiam fazer ainda melhor adicionando outro mecanismo. Digite PNL.

O Processamento de Linguagem Natural, que é a capacidade de um computador de entender a fala humana enquanto é falada, é um vasto campo em si mesmo, muitas vezes aproveitado por meio de APIs de análise de sentimento .
Os mecanismos exatos por trás da PNL estão além do escopo deste artigo, mas eis o que acontece em um nível muito alto: o Spotify rastreia a Web constantemente procurando por posts e outros textos escritos sobre música para descobrir o que as pessoas estão dizendo sobre artistas e músicas específicas - quais adjetivos e qual linguagem em particular é freqüentemente usada em referência a esses artistas e músicas, e quais outros artistas e músicas também estão sendo discutidos ao lado deles.
Embora eu não saiba os detalhes de como o Spotify opta por processar esses dados copiados, posso oferecer algumas dicas com base em como o Echo Nest costumava trabalhar com eles. Eles colocariam os dados do Spotify no que eles chamam de "vetores culturais" ou "termos principais". Cada artista e música tinha milhares de termos importantes que mudavam no dia a dia. Cada termo tinha um peso associado, que se correlacionava com sua importância relativa - aproximadamente, a probabilidade de alguém descrever a música ou o artista com esse termo.

Para descobrir quais gostos musicais dos usuários são mais parecidos com os meus, a filtragem colaborativa compara meu vetor com todos os vetores dos outros usuários, definindo quais usuários são as correspondências mais próximas. O mesmo vale para o vetor Y, músicas : você pode comparar o vetor de uma única música com todas as outras e descobrir quais músicas são mais parecidas com a que está em questão.
A filtragem colaborativa faz um bom trabalho, mas o Spotify sabia que eles poderiam fazer ainda melhor adicionando outro mecanismo. Digite PNL.
Modelo de Recomendação nº 2: Processamento de Linguagem Natural (PNL)
O segundo tipo de modelos de recomendação que o Spotify emprega são os modelos de Processamento de Linguagem Natural (PNL) . Os dados de origem para esses modelos, como o nome sugere, são palavras comuns : rastrear metadados, artigos de notícias, blogs e outros textos pela Internet.O Processamento de Linguagem Natural, que é a capacidade de um computador de entender a fala humana enquanto é falada, é um vasto campo em si mesmo, muitas vezes aproveitado por meio de APIs de análise de sentimento .
Os mecanismos exatos por trás da PNL estão além do escopo deste artigo, mas eis o que acontece em um nível muito alto: o Spotify rastreia a Web constantemente procurando por posts e outros textos escritos sobre música para descobrir o que as pessoas estão dizendo sobre artistas e músicas específicas - quais adjetivos e qual linguagem em particular é freqüentemente usada em referência a esses artistas e músicas, e quais outros artistas e músicas também estão sendo discutidos ao lado deles.
Embora eu não saiba os detalhes de como o Spotify opta por processar esses dados copiados, posso oferecer algumas dicas com base em como o Echo Nest costumava trabalhar com eles. Eles colocariam os dados do Spotify no que eles chamam de "vetores culturais" ou "termos principais". Cada artista e música tinha milhares de termos importantes que mudavam no dia a dia. Cada termo tinha um peso associado, que se correlacionava com sua importância relativa - aproximadamente, a probabilidade de alguém descrever a música ou o artista com esse termo.
"Vetores culturais" ou "termos principais", usados pelo Echo Nest. Fonte da imagem: Como a recomendação musical funciona - e não funciona , por Brian Whitman, co-fundador do The Echo Nest.
Então, assim como na filtragem colaborativa, o modelo de PNL usa esses termos e pesos para criar uma representação vetorial da música que pode ser usada para determinar se duas músicas são semelhantes. Legal certo?

Primeiro, uma pergunta. Você pode estar pensando:
Em primeiro lugar, adicionar um terceiro modelo melhora ainda mais a precisão do serviço de recomendação de músicas. Mas esse modelo também serve a um propósito secundário: ao contrário dos dois primeiros tipos, os modelos de áudio bruto levam em conta novas músicas.
Veja, por exemplo, uma música que seu amigo cantor e compositor colocou no Spotify. Talvez ele tenha apenas 50 ouvintes, então há poucos outros ouvintes para filtrá-lo de forma colaborativa. Ele também não é mencionado em nenhum lugar na internet ainda, então os modelos de PNL não vão buscá-lo. Felizmente, os modelos de áudio bruto não discriminam entre novas faixas e faixas populares, então, com a ajuda deles, a música do seu amigo pode acabar em uma lista de reprodução do Discover Weekly juntamente com músicas populares!
Mas como podemos analisar dados de áudio brutos , que parecem tão abstratos?
Com redes neurais convolucionais !
As redes neurais por convolução são a mesma tecnologia usada no software de reconhecimento facial. No caso do Spotify, eles foram modificados para uso em dados de áudio em vez de pixels. Aqui está um exemplo de uma arquitetura de rede neural:

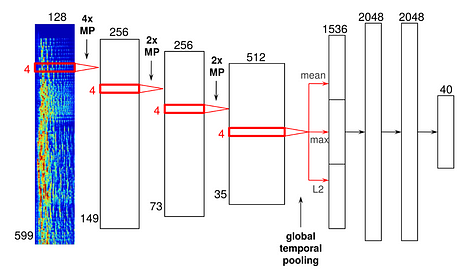
Então, assim como na filtragem colaborativa, o modelo de PNL usa esses termos e pesos para criar uma representação vetorial da música que pode ser usada para determinar se duas músicas são semelhantes. Legal certo?
Modelo de Recomendação n.º 3: Modelos de Áudio Brutos
Primeiro, uma pergunta. Você pode estar pensando:
Sophia, já temos muitos dados dos dois primeiros modelos! Por que precisamos analisar o áudio em si também?
Veja, por exemplo, uma música que seu amigo cantor e compositor colocou no Spotify. Talvez ele tenha apenas 50 ouvintes, então há poucos outros ouvintes para filtrá-lo de forma colaborativa. Ele também não é mencionado em nenhum lugar na internet ainda, então os modelos de PNL não vão buscá-lo. Felizmente, os modelos de áudio bruto não discriminam entre novas faixas e faixas populares, então, com a ajuda deles, a música do seu amigo pode acabar em uma lista de reprodução do Discover Weekly juntamente com músicas populares!
Mas como podemos analisar dados de áudio brutos , que parecem tão abstratos?
Com redes neurais convolucionais !
As redes neurais por convolução são a mesma tecnologia usada no software de reconhecimento facial. No caso do Spotify, eles foram modificados para uso em dados de áudio em vez de pixels. Aqui está um exemplo de uma arquitetura de rede neural:
Fonte da imagem: Recomendando música no Spotify com deep learning , Sander Dieleman.
Esta rede neural particular tem quatro camadas convolucionais , vistas como as barras grossas à esquerda, e três camadas densas, vistas como as barras mais estreitas à direita. As entradas são representações de freqüência de tempo de quadros de áudio, que são então concatenados, ou ligados entre si, para formar o espectrograma.
Os quadros de áudio passam por essas camadas convolucionais e, depois de passar pelo último, é possível ver uma camada de “agrupamento temporal global”, que se agrupa ao longo de todo o eixo do tempo, computando estatísticas dos recursos aprendidos ao longo do tempo da música.
Após o processamento, a rede neural cria um entendimento da música, incluindo características como tempo estimado , tecla, modo, andamentoe volume. Abaixo está um gráfico de dados para um trecho de 30 segundos de "Around the World", de Daft Punk.


Esta rede neural particular tem quatro camadas convolucionais , vistas como as barras grossas à esquerda, e três camadas densas, vistas como as barras mais estreitas à direita. As entradas são representações de freqüência de tempo de quadros de áudio, que são então concatenados, ou ligados entre si, para formar o espectrograma.
Os quadros de áudio passam por essas camadas convolucionais e, depois de passar pelo último, é possível ver uma camada de “agrupamento temporal global”, que se agrupa ao longo de todo o eixo do tempo, computando estatísticas dos recursos aprendidos ao longo do tempo da música.
Após o processamento, a rede neural cria um entendimento da música, incluindo características como tempo estimado , tecla, modo, andamentoe volume. Abaixo está um gráfico de dados para um trecho de 30 segundos de "Around the World", de Daft Punk.
Fonte da imagem: Tristan Jehan e David DesRoches, via The Echo Nest .
Em última análise, esta leitura das principais características da música permite ao Spotify entender semelhanças fundamentais entre as músicas e, portanto, quais usuários podem aproveitá-las, com base em seu próprio histórico de audição.
Isso abrange as noções básicas dos três principais tipos de modelos de recomendação que alimentam o Pipeline de Recomendações do Spotify e, em última análise, aciona a lista de reprodução do Discover Weekly!
É claro, esses modelos de recomendação estão todos conectados ao ecossistema maior do Spotify, que inclui grandes quantidades de armazenamento de dados e usa muitos clusters do Hadoop para escalar recomendações e fazer com que esses mecanismos trabalhem em matrizes enormes, infinitos artigos de música on-line e grande número de arquivos de áudio .
Espero que isso tenha sido informativo e tenha despertado sua curiosidade como se fosse minha. Por enquanto, estarei trabalhando em meu próprio Discover Weekly, encontrando minha nova música favorita enquanto aprecio todo o aprendizado de máquina que está ocorrendo nos bastidores. 🎶





